什么是 Knowledge Tracing?
Knowledge Tracing,中文知识追踪,可以理解为 IRT(Item Response Theory)在深度学习时代的新马甲。本质上,Knowledge Tracing(aka. KT)的目的是根据学生的历史做题记录评估他对不同知识点的掌握状态(在 KT 领域,这件事情被称为 Knowledge Estimation,知识估计)。
然而因为掌握状态其实是一个 Hidden State,我们并没有直接的监督信号能够给出学生对一个知识点的掌握是 10% 还是 30%,因此,目前的工作更多是在通过预测学生在没有见过的题目上的正确情况,去检验模型知识估计的准确性。
传统的 IRT 需要被深度学习方法所替代的原因有多方面。首先,传统的 IRT 主要依赖于对试题和学生能力的静态建模,通常假设题目难度和学生能力是固定的。然而,学生的学习过程是动态的,随着时间的推移,学生的能力会发生变化。IRT 的静态假设无法有效捕捉这种动态变化。此外,传统的 IRT 在处理复杂的题目特征和学生的多样化反应模式时显得力不从心。学生在学习过程中可能会遇到不同类型的题目,这些题目可能涉及多种知识点和技能,传统的 IRT 难以全面建模这些复杂关系。
深度学习方法能够更好地捕捉这些动态变化和复杂关系,从而提供更精确的知识估计。深度学习模型可以通过大量数据训练,自动学习到学生能力变化的模式和题目特征之间的复杂关系。
例如,在验证学生对「全等性」掌握程度的题目中,
- 题目 1(简单) 给定两个三角形 ABC 和 DEF,已知 AB = DE, AC = DF, ∠BAC = ∠EDF。请证明三角形 ABC 和 DEF 全等。
- 题目 2(困难) 在一个平行四边形 ABCD 中,E 和 F 分别是边 AD 和 BC 上的点,且 AE = BF。已知 ∠EAB = ∠FBA。请证明三角形 ABE 和三角形 CDF 全等。
如果只是简单地把题目和知识点进行关联,然后建立(知识点,对错)到掌握情况的映射,会失去对难度的建模。能完成题目 1 和能完成题目 2 对全等的掌握情况是不同的。传统的 IRT 难以捕捉这种细微的差异,而深度学习方法则可以通过复杂的模型结构来更好地建模这些差异。其实,除开难度,学生的完成情况,比如完全不会做和能完成一部分步骤也是有很大差异的,对完成情况进行考虑,我们称之为 Open-ended Knowledge Tracing。但这样的数据集比较难获取,目前大部分的工作还是在只包含选择题的数据集上做。
此外,传统 IRT 模型通常假设学生的反应是独立的,忽略了学生在学习过程中的累积效应和先前知识的影响。深度学习方法可以通过序列模型捕捉学生学习过程中的时间依赖性,从而更准确地预测学生未来的表现。
$$ P(X_{ij} = 1 | \theta_i, \beta_j) = \frac{1}{1 + e^{-(\theta_i - \beta_j)}} \tag 1 $$IRT的计算公式,其中 $\theta_i$ 表示学生 $i$ 的能力水平,$\beta_j$ 表示题目 $j$ 的难度参数。$P(X_{ij} = 1 | \theta_i, \beta_j)$ 表示学生 $i$ 正确回答题目 $j$ 的概率。
IRT模型其实本质上就是一个简单的 logistic regression,后来C Piech等人提出了 Deep Knowledge Tracing (DKT)作为神经网络在 KT 领域的开山之作,具体来说,DKT 使用了循环神经网络(RNN)来捕捉学生在学习过程中的时间依赖性。通过输入学生的历史答题记录,DKT 模型能够动态更新学生的知识状态,并预测他们在未来题目上的表现。DKT 的提出极大地推动了知识追踪领域的发展,后续的研究也在此基础上不断改进和扩展。
Knowledge Tracing 具有代表性的工作
在我看来 Knowledge Tracing 最具有代表性的工作无非是两篇,DKT[1] 和 AKT[2],这两篇文章分别代表了两个经典的网络,RNN 和 Transformer。

图 1:DKT 模型
DKT 模型使用循环神经网络(RNN)来捕捉学生在学习过程中的时间依赖性。通过输入学生的历史答题记录,DKT 模型能够动态更新学生的知识状态,并预测他们在未来题目上的表现。

图 2:AKT 模型
AKT 模型使用了 Transformer 结构,通过引入注意力机制来捕捉学生在学习过程中的上下文信息。AKT 模型能够更好地建模学生的知识状态,并在预测学生未来表现时取得更高的准确性。
AKT一个非常有创意的工作是单调注意力机制和 Rasch Embedding。单调注意力机制通过确保注意力权重随时间步长单调递增,从而捕捉学生知识状态的累积效应。其公式如下:
$$ \alpha_t = \frac{\exp(e_t)}{\sum_{k=1}^{t} \exp(e_k)} \tag 2 $$其中,$\alpha_t$ 表示时间步长 $t$ 的注意力权重,$e_t$ 表示时间步长 $t$ 的注意力得分。
而 Rasch Embedding 则通过将题目难度和学生能力嵌入到同一向量空间中,使得模型能够更好地建模学生与题目之间的关系。其公式如下:
$$ P(X_{ij} = 1 | \theta_i, \beta_j) = \frac{1}{1 + e^{-(\theta_i - \beta_j)}} \tag 3 $$其中,$\theta_i$ 表示学生 $i$ 的能力水平,$\beta_j$ 表示题目 $j$ 的难度参数,$P(X_{ij} = 1 | \theta_i, \beta_j)$ 表示学生 $i$ 正确回答题目 $j$ 的概率。
Knowledge Tracing 研究的问题
我在西南大学读书时,我的研究方向就是 Knowledge Tracing,当时顶会里也有很多关于 KT的工作,比如 GKT[4],ATKT[5],IEKT[6]等。这些工作的引用量都相对较大,比如 GKT 的引用量达到了363(截至 2025/02/14)。然而我对这些模型尝试进行复现的效果并不好,起初我只是认为是复现的问题。知道后来,Zitao Liu 等人在 NeuralIPS 上发表了 PyKT[3] 这项可以说是撕开大家遮羞布的工作,我才意识到可能是其他的原因。
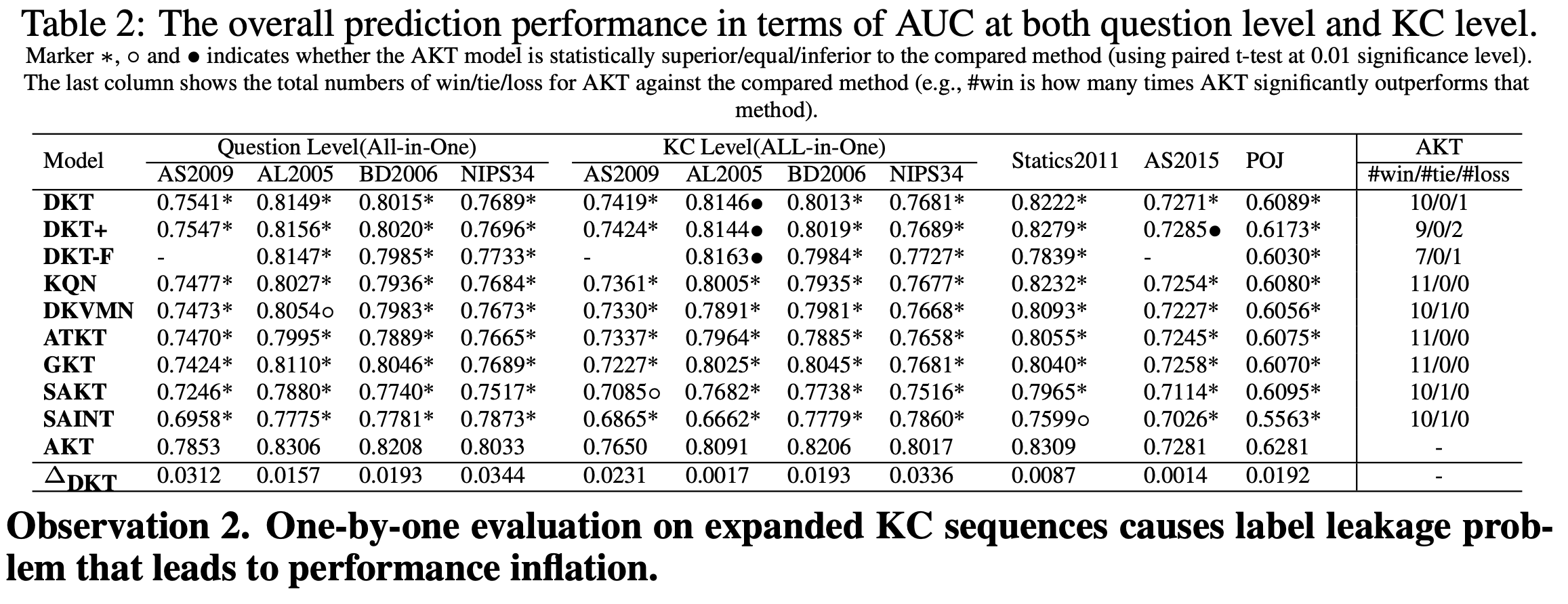
图 3:PyKT 实验结果。
PyKT展示了不同知识追踪模型在多个数据集上的表现。具体来说,表格中列出了 DKT、DKVMN、SAKT、AKT 和 GKT 等模型在ASSISTments2009、ASSISTments2015、Statics2011 和 Synthetic-5 数据集上的 AUC和指标。可以看到一个让人吃惊的事实,即使是和 vanillia LSTM (DKT) 比,大部分的模型都是没有什么提升的。
这里详细解释一下 PyKT 的实验设置以及motivation。
PyKT发现,之前大家对 KT 的实验都是存在数据泄露的,这是因为大部分的模型是通过预测知识点的准确率来评估模型性能,而并非是直接预测题目的准确率。这存在什么问题呢?
(Q1)在一个平面直角坐标系中,已知点A(0, 0),点B(6, 0),点C(0, 8)构成一个直角三角形。点D是线段AB上的一个点,且满足AD:DB=2:1。以下哪个选项是点D到直线BC的距离?
这个题目包含了以下知识点:
- 勾股定理(KC1):用于验证三角形ABC是直角三角形。
- 分点公式(KC2):用于确定点D的坐标。
- 点到直线的距离公式(KC3):用于计算点D到直线BC的距离。
KT的实验设置并非是直接验证学生在 Q1 上的准确率,而是把 Q1 分解为 KC1, KC2, KC3,然后连续验证三次。这种设置会导致标签泄露问题,因为连续的知识点(如 kt 和 kt+1)可能与同一个问题相关联,这就给模型额外的约束。PyKT 的实验揭示了这种数据泄露对模型性能的提升。
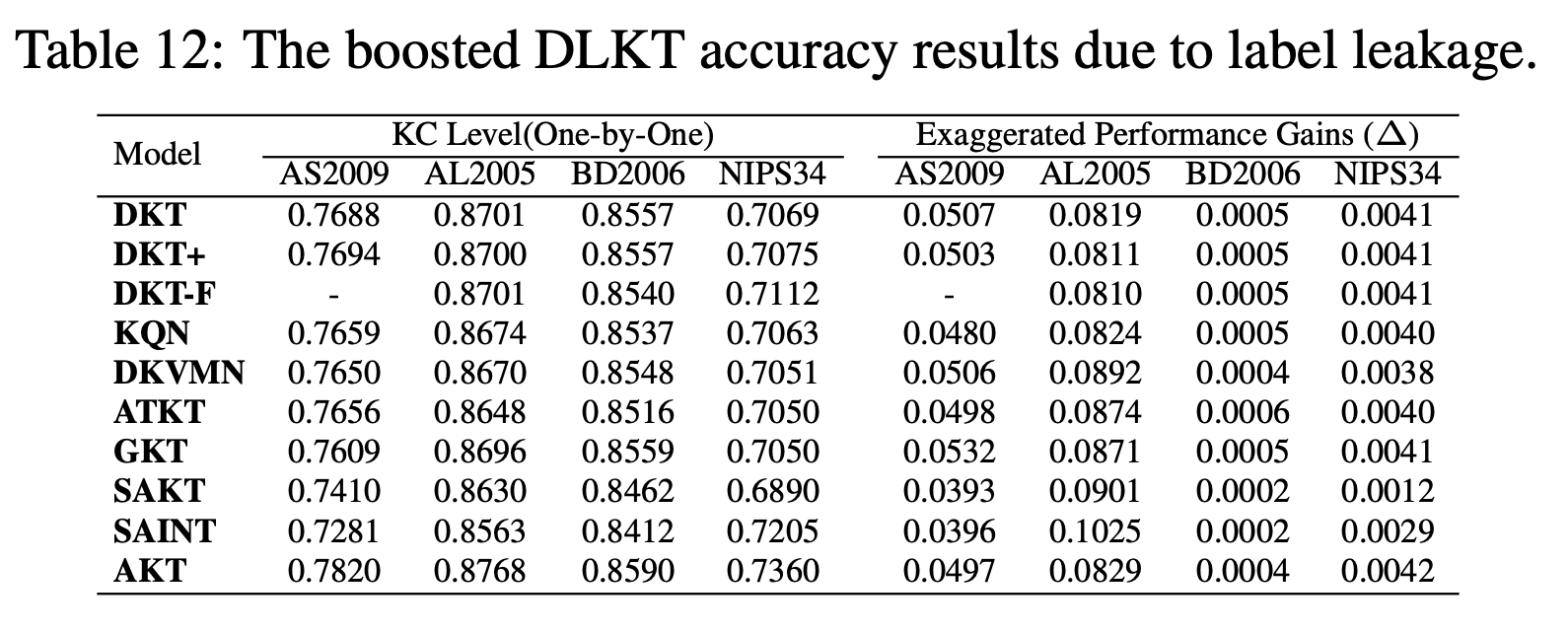
图 4:数据泄露对模型的提升
可以看到,数据泄露给模型们大概带来了不小的收益。此外,大部分模型的实验还存在典型的因为实验设置的问题导致的不公平对比的现象,图 3 的实验结果指出,如果用标准的实验设置,现有的 SOTA 应该是 AKT,其次是 DKT。
PyKT 援引的工作都是 KT 领域的高引论文,这就在告诉我们,这十年来大家都白干了。 PyKT 还发现,ATKT 的实验存在严重的数据泄露问题,模型甚至没有 causal masking,能够直接看到未来的交互。
Knowledge Tracing 的迷思
PyKT 对这个问题的解释是,Knowledge Tracing 的数据太稀疏,用复杂的网络,比如 Attention 和 Graph Neural Network 反而容易导致过拟合。这也和我的体验高度一致,在复现很多论文的时候大部分方法是非常不稳定的,除了 AKT,几乎没有模型是可以稳固提升。
对于 KT 领域,我也是颇有微词。比如某个大组,常年在自己私有的数据集上做实验,不开放或者很少开放源码,复现难度很高。很多工作做得还非常复杂,让人不禁怀疑,他们真的不会过拟合吗?
再比如最近发现的一个骚操作,某作者用线性偏置同期发表了两篇文章。这里简单介绍一下线性偏置的主要思想。之前的 Attention-based 模型,在长序列上的泛化能力比较差,这是因为 Attention 是在整个序列上做,如果用一个权重矩阵来描述interaction 之间的因果关系
那么,什么是因果关系呢?其实就是指不同的interactions(做题记录)之间是否能够相互促进,这种因果依存关系可以通过一个 $L \times L$ 的矩阵来描述,其中矩阵的权重可以理解为interactions之间相互促进的重要性。这揭示了题目与题目之间的相关性。
但正如我们之前所讲,KT 的数据集其实非常稀疏,因此 interactions 之间的因果依存不一定能被学得很好。为了解决这个问题,我们可以人工地设置一个线性偏置,强行让模型认识到,要更关注当前 interaction 附近的 interactions。这也有很好的直观解释,学生的知识状态在不断变化,聚焦当下对模型来说比关注过去更重要。
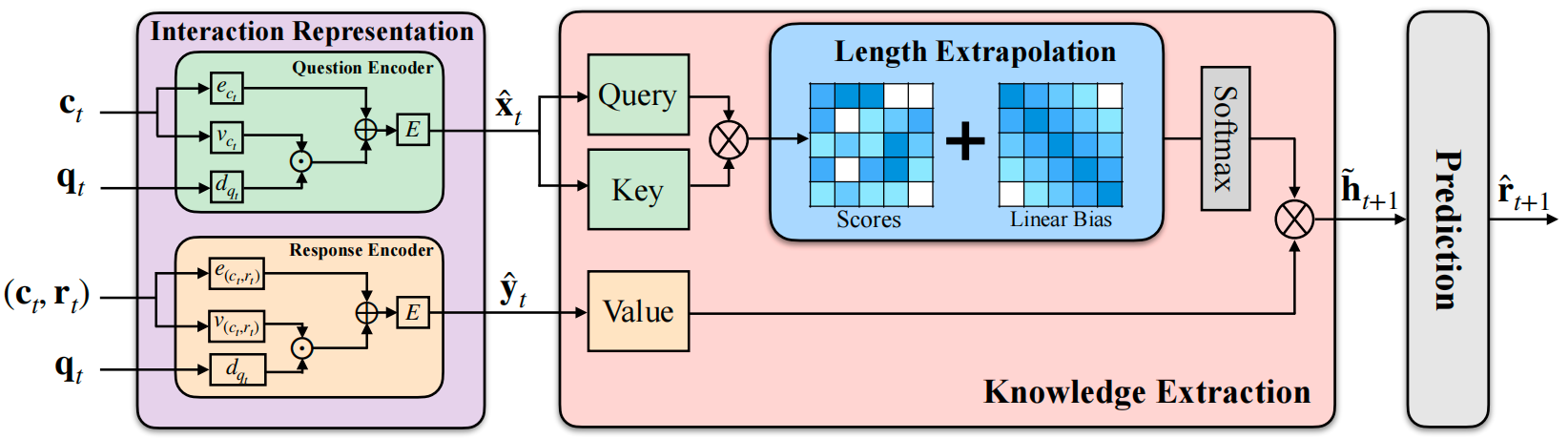 图 5 ExtraKT[7]
图 5 ExtraKT[7]
图 5 是这种方案的一个示意图,其实就是给 Scores 进行加权。这个思想本身并不来自 KT 领域,而是来自Press O等人的工作[10]。经过更仔细的文献调研,我发现,不仅仅是 ExtraKT,StableKT[8] 和FoLiBiKT[9]都用了同样的方法。
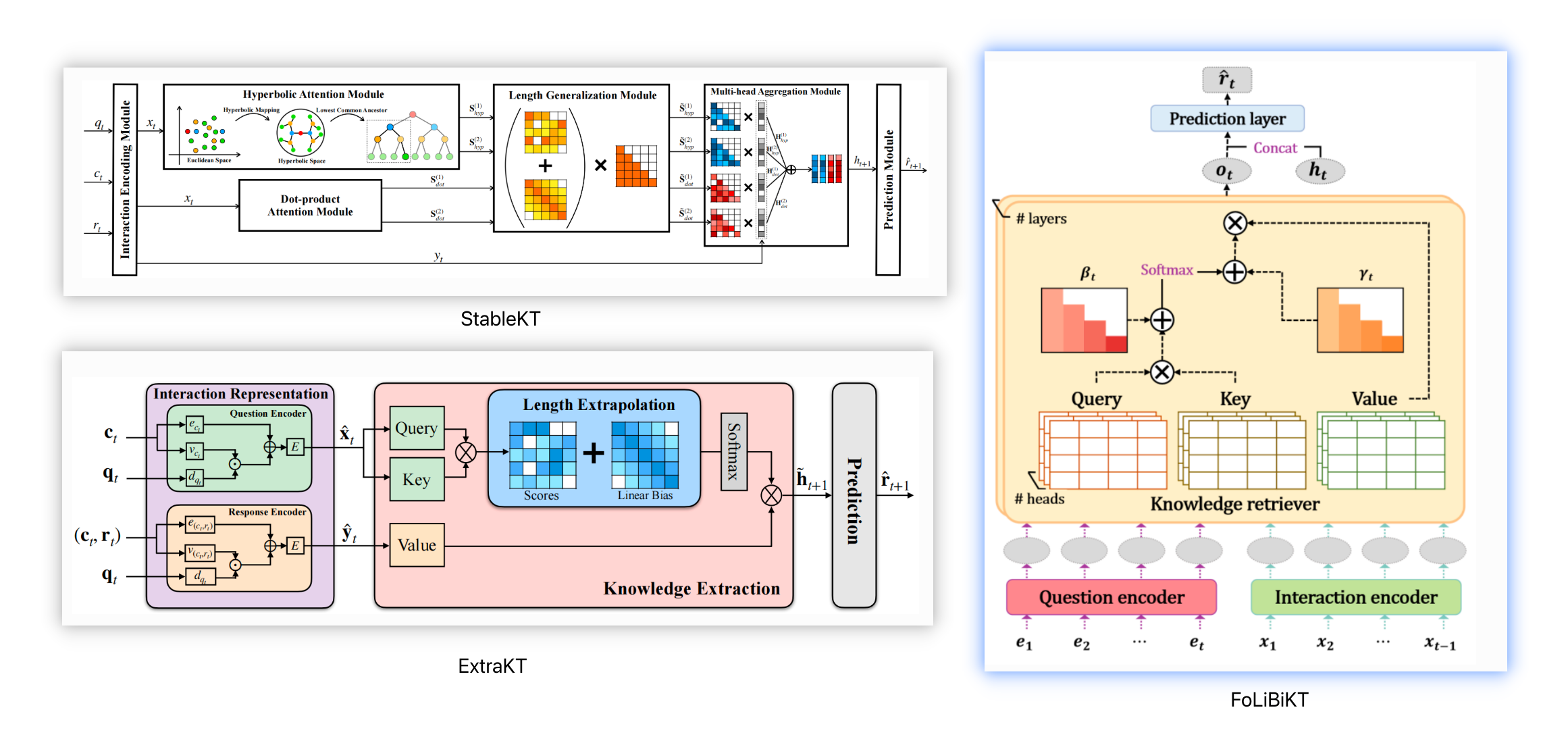 图 6 StableKT(ECAI 2024, Li X et al.), ExtraKT(IJCAI 2024, Li X et al.) and FoLiBiKT(CIKM 2023, Im, Yoonjin et al.)
图 6 StableKT(ECAI 2024, Li X et al.), ExtraKT(IJCAI 2024, Li X et al.) and FoLiBiKT(CIKM 2023, Im, Yoonjin et al.)
这三份工作的核心贡献都是把 Linear Bias 融入到 Attention Map 里,嗯…其中两篇还是来自同一个作者。
Knowledge Tracing 的工作大家推荐了这么多年,很多工作的意义只在于发论文,最终真实的性能其实并不比 DKT 强,归根结底还是 KT 这个任务太简单了,RNN 就能取得很好的效果,但另一方面 KT 这个任务又太重要了,以至于大家还是希望在这个任务上取得更多的进展。
Future of Knowledge Tracing
Opened Knowledge Tracing
知识追踪在常规试题上相对简单,或许在 Programming Knowledge Tracing 或者类似的 Opened Knowledge Tracing 任务上会更有空间做进一步的工作。
一方面,Programming Knowledge Tracing 如果能够拿到 leetcode / codeforces 的数据,那是很好可以去探索学习者在不同知识点上的掌握情况的——数据量足够多。即使不能,能够拿到历年学校编程练习的数据,也是很好的。
另一方面,与传统的 Knowledge Tracing不同,Programming Knowledge Tracing 能够拿到题目的文本信息,以及学生的完整做题结果,甚至是每次提交的情况(能完整地刻画学生的知识状态变化,甚至可以让模型找到学生的 aha moment)。此外,我们不仅仅可以去预测学生最终有没有 AC,AC了哪些数据点,甚至还能根据学生的历史代码风格去做代码生成,看模型有没有学到学生的编程风格(甚至可以拿来做代码剽窃检测)。
总之,Programming Knowledge Tracing 能够提供非常细粒度的数据,只可惜目前做这个领域的还不是很多。至于基于 IDs 的简单数据集,我想的确是已经没有太多空间可以去发挥了。
reference
[1]. Piech C, Bassen J, Huang J, et al. Deep knowledge tracing[J]. Advances in neural information processing systems, 2015, 28.
[2]. Ghosh A, Heffernan N, Lan A S. Context-aware attentive knowledge tracing[C]//Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020: 2330-2339.
[3]. Liu Z, Liu Q, Chen J, et al. pyKT: a python library to benchmark deep learning based knowledge tracing models[J]. Advances in Neural Information Processing Systems, 2022, 35: 18542-18555.
[4].Nakagawa H, Iwasawa Y, Matsuo Y. Graph-based knowledge tracing: modeling student proficiency using graph neural network[C]//IEEE/WIC/ACM International Conference on Web Intelligence. 2019: 156-163.
[5].Guo X, Huang Z, Gao J, et al. Enhancing knowledge tracing via adversarial training[C]//Proceedings of the 29th ACM International Conference on Multimedia. 2021: 367-375.
[6].Long T, Liu Y, Shen J, et al. Tracing knowledge state with individual cognition and acquisition estimation[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 173-182.
[7].Li X, Bai Y, Guo T, et al. “Extending Context Window of Attention Based Knowledge Tracing Models via Length Extrapolation.” Proceedings of the 26th European Conference on Artificial Intelligence. 2024.
[8].Li X, Bai Y, Guo T, et al. “Enhancing Length Generalization for Attention Based Knowledge Tracing Models with Linear Biases.” Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 2024.
[9].Im, Yoonjin, et al. “Forgetting-aware Linear Bias for Attentive Knowledge Tracing.” Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2023.
[10].Press O, Smith N A, Lewis M. Train short, test long: Attention with linear biases enables input length extrapolation[J]. arXiv preprint arXiv:2108.12409, 2021.